在后端面试中常被问到Mysql相关内容,这里整理了下面试中常被问到的mysql问题。 不是很全,后面遇到后会慢慢补充。
1.MySQL的事务隔离级别
未提交读(Read Uncommitted)
允许脏读,其他事务只要修改了数据,即使未提交,本事务也能看到修改后的数据值。也就是可能读取到其他会话中未提交事务修改的数据
提交读(Read Committed)
只能读取到已经提交的数据。Oracle等多数数据库默认都是该级别 (不重复读)。
可重复读(Repeated Read)
可重复读。无论其他事务是否修改并提交了数据,在这个事务中看到的数据值始终不受其他事务影响。
串行读(Serializable)
完全串行化的读,每次读都需要获得表级共享锁,读写相互都会阻塞
MySQL数据库(InnoDB引擎)默认使用可重复读( Repeatable read)
2.存储引擎 MyISAM和InnoDB区别
1)InnoDB支持事务,MyISAM不支持。
2)MyISAM适合查询以及插入为主的应用,InnoDB适合频繁修改以及涉及到安全性较高的应用。
3)InnoDB支持外键,MyISAM不支持。
4)从MySQL5.5.5以后,InnoDB是默认引擎。
5)MyISAM支持全文类型索引,而InnoDB不支持全文索引。
6)InnoDB中不保存表的总行数,select count() from table时,InnoDB需要扫描整个表计算有多少行,但MyISAM只需简单读出保存好的总行数即可。注:当count()语句包含where条件时MyISAM也需扫描整个表。
7)对于自增长的字段,InnoDB中必须包含只有该字段的索引,但是在MyISAM表中可以和其他字段一起建立联合索引。
8)清空整个表时,InnoDB是一行一行的删除,效率非常慢。MyISAM则会重建表。MyisAM使用delete语句删除后并不会立刻清理磁盘空间,需要定时清理,命令:OPTIMIZE table dept;
9)InnoDB支持行锁(某些情况下还是锁整表,如 update table set a=1 where user like ‘%lee%’)
10)Myisam创建表生成三个文件:.frm 数据表结构 、 .myd 数据文件 、 .myi 索引文件,Innodb只生成一个 .frm文件,数据存放在ibdata1.log
现在一般都选用InnoDB,主要是MyISAM的全表锁,读写串行问题,并发效率锁表,效率低,MyISAM对于读写密集型应用一般是不会去选用的。
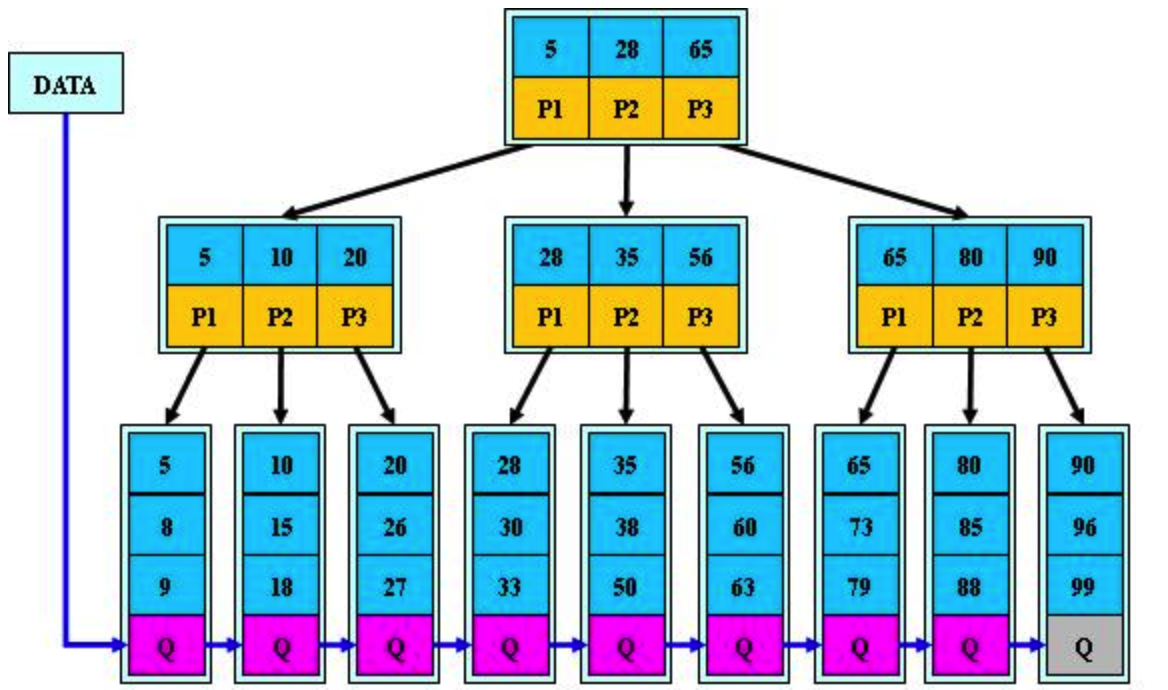
3.mysql为什么使用B+树作为索引的结构
1.B+树的中间节点不保存数据,是纯索引,但是B树的中间节点是保存数据和索引的,相对来说,B+树磁盘页能容纳更多节点元素,更“矮胖”;
2.B+树查询必须查找到叶子节点,B树只要匹配到即可不用管元素位置,因此b+树查找更稳定(并不慢);
3.对于范围查找来说,B+树只需遍历叶子节点链表即可,B树却需要重复地中序遍历,在项目中范围查找又很是常见的
4.增删文件(节点)时,效率更高,因为B+树的叶子节点包含所有关键字,并以有序的链表结构存储,这样可很好提高增删效率。
如下图:
更多树相关参考:https://blog.csdn.net/a314774167/article/details/88111713
4.MySQL如何进行SQL优化?
(1)选择正确的存储引擎
两个存储引擎 MyISAM 和 InnoDB,每个引擎都有利有弊。
MyISAM 适合于一些需要大量查询的应用,但其对于有大量写操作并不是很好。甚至你只是需要update一个字段,整个表都会被锁起来,而别的进程,就算是读进程都无法操作直到读操作完成。另外,MyISAM 对于 SELECT COUNT(*) 这类的计算是超快无比的。
InnoDB 的趋势会是一个非常复杂的存储引擎,对于一些小的应用,它会比 MyISAM 还慢。但是它支持“行锁”,于是在写操作比较多的时候,会更优秀。并且,他还支持更多的高级应用,比如:事务。
(2)优化字段的数据类型
记住一个原则,越小的列会越快。如果一个表只会有几列罢了(比如说字典表,配置表),那么,我们就没有理由使用 INT 来做主键,使用 MEDIUMINT, SMALLINT 或是更小的 TINYINT 会更经济一些。如果你不需要记录时间,使用 DATE 要比 DATETIME 好得多。当然,你也需要留够足够的扩展空间。
(3)为搜索字段添加索引
索引并不一定就是给主键或是唯一的字段。如果在你的表中,有某个字段你总要会经常用来做搜索,那么最好是为其建立索引,除非你要搜索的字段是大的文本字段,那应该建立全文索引。
(4)避免使用Select 从数据库里读出越多的数据,那么查询就会变得越慢。并且,如果你的数据库服务器和WEB服务器是两台独立的服务器的话,这还会增加网络传输的负载。即使你要查询数据表的所有字段,也尽量不要用通配符,善用内置提供的字段排除定义也许能给带来更多的便利。
(5) 使用 ENUM 而不是 VARCHAR
ENUM 类型是非常快和紧凑的。在实际上,其保存的是 TINYINT,但其外表上显示为字符串。这样一来,用这个字段来做一些选项列表变得相当的完美。例如,性别、民族、部门和状态之类的这些字段的取值是有限而且固定的,那么,你应该使用 ENUM 而不是 VARCHAR。
(6) 尽可能的使用 NOT NULL
除非你有一个很特别的原因去使用 NULL 值,你应该总是让你的字段保持 NOT NULL。 NULL其实需要额外的空间,并且,在你进行比较的时候,你的程序会更复杂。 当然,这里并不是说你就不能使用NULL了,现实情况是很复杂的,依然会有些情况下,你需要使用NULL值。
(7)固定长度的表会更快
如果表中的所有字段都是“固定长度”的,整个表会被认为是 “static” 或 “fixed-length”。 例如,表中没有如下类型的字段: VARCHAR,TEXT,BLOB。只要你包括了其中一个这些字段,那么这个表就不是“固定长度静态表”了,这样,MySQL 引擎会用另一种方法来处理。
固定长度的表会提高性能,因为MySQL搜寻得会更快一些,因为这些固定的长度是很容易计算下一个数据的偏移量的,所以读取的自然也会很快。而如果字段不是定长的,那么,每一次要找下一条的话,需要程序找到主键。
并且,固定长度的表也更容易被缓存和重建。不过,唯一的副作用是,固定长度的字段会浪费一些空间,因为定长的字段无论你用不用,他都是要分配那么多的空间。
4.MySQL索引优化?
1.尽量使用完全索引
2.最佳左前缀法则(符合索引),在查询时使用索引左边的多个字段(不能跳过某个字段)
3.不要在索引列上做任何操作,比如计算、使用函数、自动或手动进行类型转换,否则索引失效
4.尽量使用覆盖索引(只访问索引的查询(索引列包含查询列)),减少select *语句
5.mysql在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描。
6.is null,is not null 也无法使用索引。
7.like以通配符开头(like ‘%aaa’)mysql索引失效会变成全表扫描操作。
参考:https://blog.csdn.net/yhl_jxy/article/details/88636685